
カバー株式会社CTO室、エンジニアのIです。
この記事ではホロアースのSREとして1年間、どのようにオブザーバビリティの向上やクラウドインフラの改善に取り組んできたか、その記録をご紹介します。
ホロアースとは
「ホロアース」は、ホロライブプロダクションのカバー株式会社が手がける、とある異世界を舞台にしたバーチャル空間プロジェクトです。ユーザー自身がアバターとして参加し、自由に世界を探索したり、ユーザー同士でコミュニケーションや創作活動を楽しんだりできるほか、ホロライブプロダクション所属のタレントが“本人の姿”で登場するイベントや、ユーザー発のアイテム・空間の共有などを通じて、バーチャルとリアルが交わる新たな体験を提供しています。
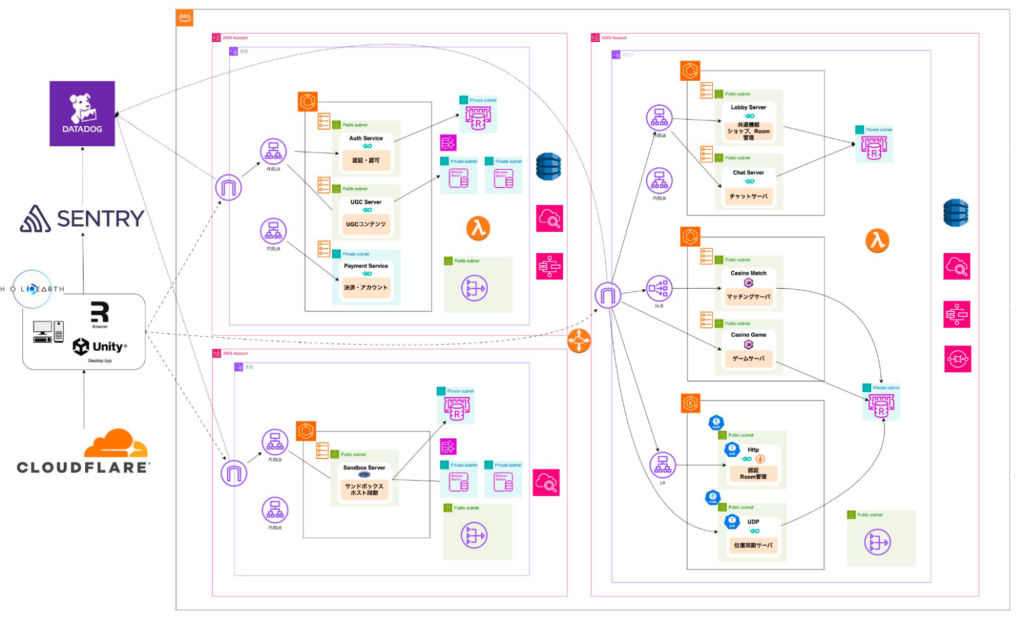
ホロアースのシステム構成とSREの活動
システム構成
ホロアースのシステムは、主にクライアント(Unity)とサーバーサイド(APIサーバー/リアルタイムサーバー)で構成されています。
- クライアント: Unity(ホロアース), Web(クリエイター用ツール)
- インフラ: EKS/ECS上で稼働
- APIサーバー: マイクロサービスとしてチームごとに様々な言語を採用
- リアルタイムサーバー: Diarkis(Go言語製のリアルタイム通信エンジン)を採用
- 監視: Sentry/Datadog
SREのロードマップと課題
私が参画した当初(2024年10月頃)、ホロアースには様々な課題がありました。
- クライアント/サーバー共に内部状態がブラックボックス化している
- 新規構築のインフラや機能開発が間に合っていない
- リアルタイムサーバーとしての安定運用ができていない
- … etc
これらを解決するため、SREチームでは以下のようなロードマップを策定し、改善を進めました。
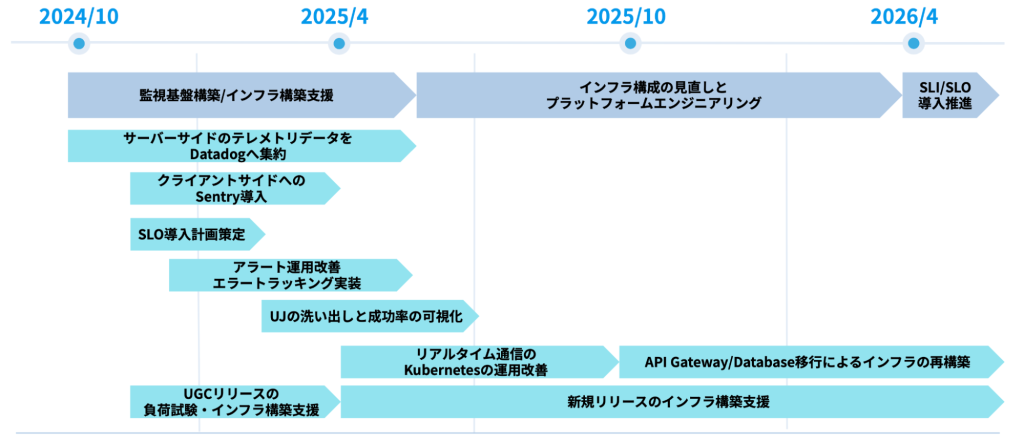
本記事でも取り上げる取り組みについてはSRE NEXT 2025のLT及びCloudNative Days Winter 2025のセッションで発表しています、ご興味ある方はご覧ください。
CNDW2025 リアルタイムサーバー運用改善 〜メタバースプラットフォームにおけるEKS運用とDatadog活用によるオートスケール実践〜
ホロアースの監視基盤構築
クライアント/サーバーサイドそれぞれの課題と設計
まずはシステムとして「何が起きているか」を知るため、オブザーバビリティの改善に着手し、最終目標であるSLI/SLO定義のための土台固めを行いました。
- クライアントサイド: 元々Backtraceを利用していましたが、ユーザー数課金のため開発者の増加に伴い継続利用が難しくなり、新たなツールを探していました。
- サーバーサイド: 複数のオブザーバビリティバックエンド(Grafana、Datadogなど)が混在していたため、統一するためにDatadogへの切り替えを目指しました。
監視基盤の整備
クライアントサイド
Unity/Web Frontend/Backendの統一的なエラートラッキングのため、サーバーのテレメトリデータを集約しているDatadogの使用を検討しました。しかし、以下の技術的制約がありました。
- Desktop UnityのSDKの対応状況:Datadogはモバイル版Unity向けのRUMを提供していますが、デスクトップ版や、WebGLのUnityビルドには対応していない
- Cloudflareにおける問題:当時Webフロントエンドの実行環境との互換性に課題があった
そのためクライアントに関してはSentryを導入し、クラッシュレポートの収集を行うようにしました。
結果として、各エンジニアチームがSentryを活用し始めました。クリティカルなエラーへの対応をリリースに含めることができ、全体のエラー数を相当数減らすことができています。
比較したサービスに関しては以下の記事をご覧ください。
サーバーサイド
ホロアースでは、AWSでワークロードを構成しており、ECS(Fargate)およびEKSを利用しています。
当時、APIサーバーの一部にDatadogが部分的に導入されていました。一方で、EKSなどの環境ではPrometheus/Grafanaが使用されていたり、新規の複数のAPIサーバーが開発されている状況でした。このタイミングで、全てのサーバーサイド監視をDatadogへ一括で統合することを決定しました。
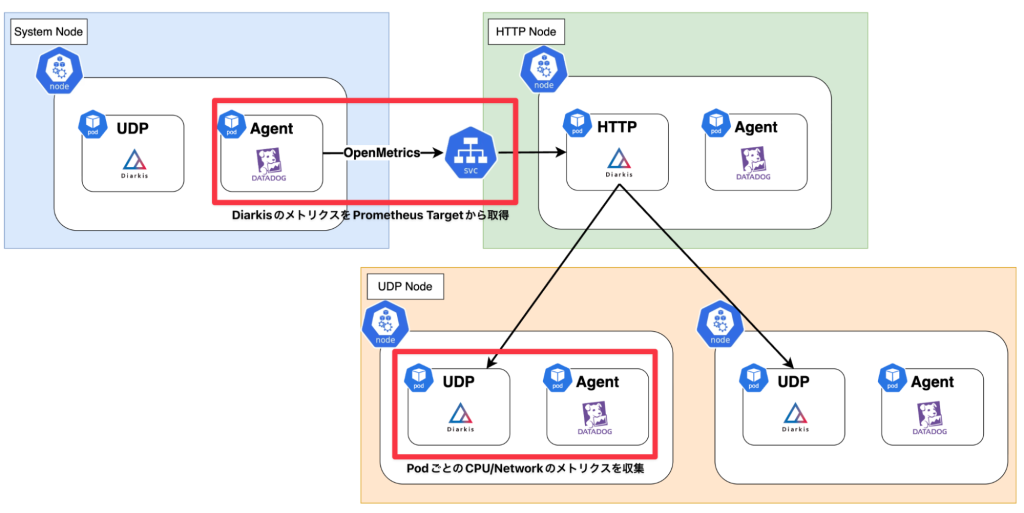
分散トレースの実装とアラート運用の改善
Datadogの導入により、AWSリソースに関するメトリクス収集は統合できましたが、アプリケーションレイヤーに近い部分の整備は十分ではありませんでした。
ホロアースのサーバーサイドはGoのサーバーが大部分を占めています。ここではDatadog Tracingを利用して計装を行っており、これらの増え続けるサーバーや設定漏れを防ぐため、ホロアースではサーバー全体をOrchestrionへ移行しました。
https://github.com/DataDog/orchestrion
Orchestrionはコンパイル時計装ツールで、既存のGo Buildプロセスに簡単に組み込むことができます。組み込み時の考慮点については、以下の記事をご覧ください。
トレース自体は送信できるようになったものの、各アプリケーションごとにタグ付けが標準化されておらず、収集しているトレースを十分に活用できていない状態でした。
そこで、タグの標準化(env、service、team)を行い、トレース同士を繋げ、サービスマップの改善を図りました。
結果として、各環境ごとの複数サービスの連携が可視化されました。これはデバッグや障害時の調査に役立っています。


ダッシュボードの工夫
元々はチームごとのダッシュボードに分かれていましたが、メンテナンスの手間や共通リソースの多さを考慮しました。そこで、一つの統合ダッシュボードとして作り直しました。
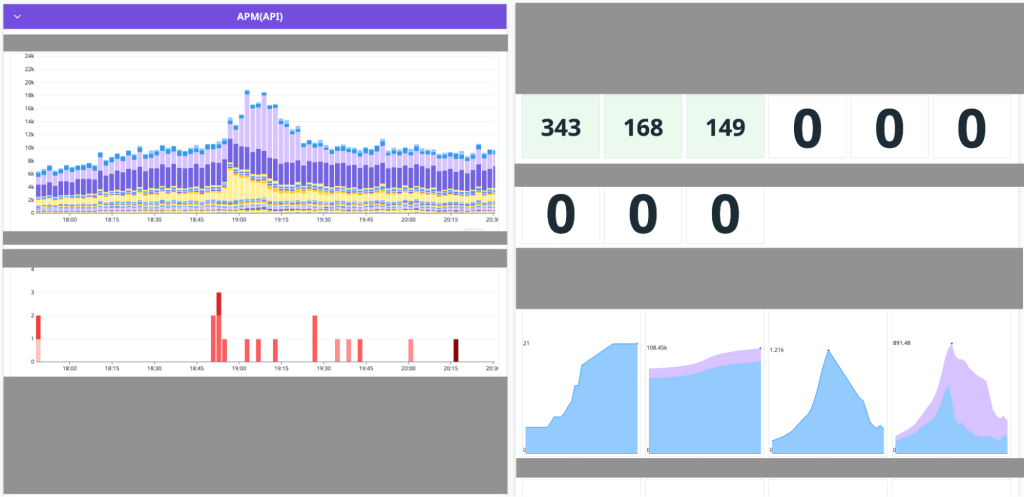
このダッシュボードでは、テンプレート変数とビューの機能を利用し、環境ごとに表示を切り替えることができます。

アラート通知の工夫
アラートはDatadog Monitorを利用し、Slackへ通知しています。
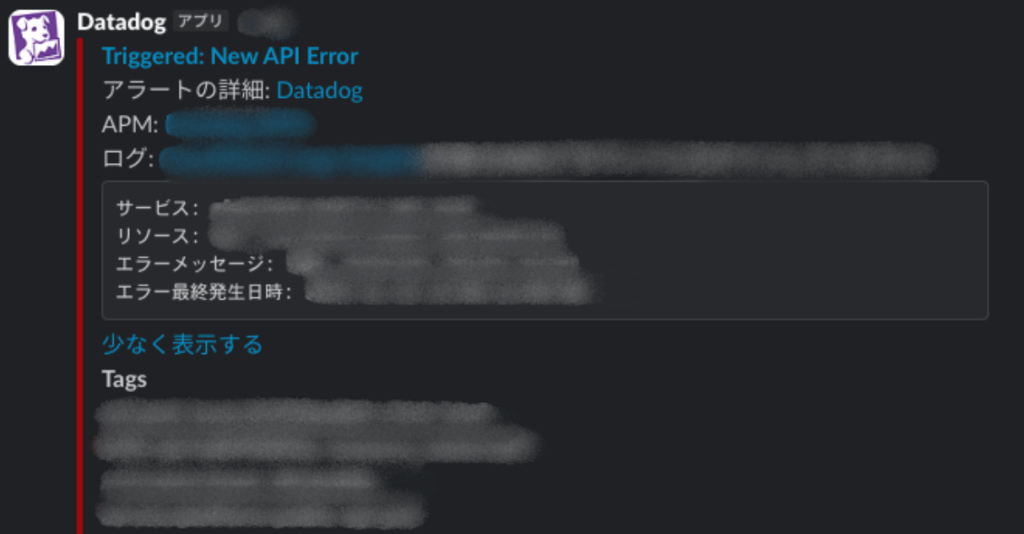
アラートの内容は、人が一目で何が起きたか把握できる情報を含めるべきです。そのため、以下の情報を含めるようにしました。
(例: APMの場合)
・エラーが起きたサービス名(環境情報も含む)
・エラーが起きたリソース名(API Endpointなど)
・エラーメッセージ
・エラーが発生した日時、発生頻度
・各種Link(APM、Runbookなど)
コスト削減
Datadogは非常に便利ですが、ユースケースに合わせてカスタマイズしないとコストが跳ね上がります。ホロアースでは、検知と対策として以下を行っています。
[検知]
・推定使用量メトリクスを利用し、一定の閾値を超えたらアラートを出すように設定する
Infra Hostやカスタムメトリクス数などが気づかないうちに増えていないか、意図せずカーディナリティの高いデータを取り込んでいないかを確認しています。
これらをチェックするため、それぞれの使用量をダッシュボード・アラート化し、定期的に確認しています。
推定使用量メトリクス
[対策]
・一部のTrace Agentを集約し、APM Host数を削減する
EKSではDatadog OperatorでAPMを有効化すると各NodeAgentにTraceAgentが内包される形になるため、アプリケーションPodからのTraceの送信先を統合するようにしています。
CNDW2025 リアルタイムサーバー運用改善 〜メタバースプラットフォームにおけるEKS運用とDatadog活用によるオートスケール実践〜
・Ingest/IndexされるSpanの量を減らす
Datadogでは、IngestおよびIndexそれぞれに従量課金が発生します。
Ingestについては、Agent側のDD_APM_IGNORE_RESOURCES等の環境変数を利用し、ヘルスチェックやLBを通過する意図しないリクエストを取り込みの対象から外しています。
IndexはRetention Filtersを元に決定されます。デフォルトのインテリジェント保持フィルターに加え、カスタムフィルターを作成し、必要なRootスパンとその子スパン以外は取り込まないようにすることで必要なSpanのみを抽出し、Monitorやダッシュボードに活用できるようにしています。
トレースの保持
リアルタイムサーバーの運用改善
監視基盤によって現状が把握できた後、EKS基盤そのもののモダナイズとオートスケールの改善に取り組みました。
元々ホロアースでは、Kubernetes上でStatefulなサーバー運用を簡素化できる商用ソフトウェアであるDiarkisを利用しています。
DiarkisのRoomモジュールを利用してEKS上のDiarkisで、同一Room内のユーザー間へのパケット(座標やエモート等のイベント)のブロードキャストを行っています。
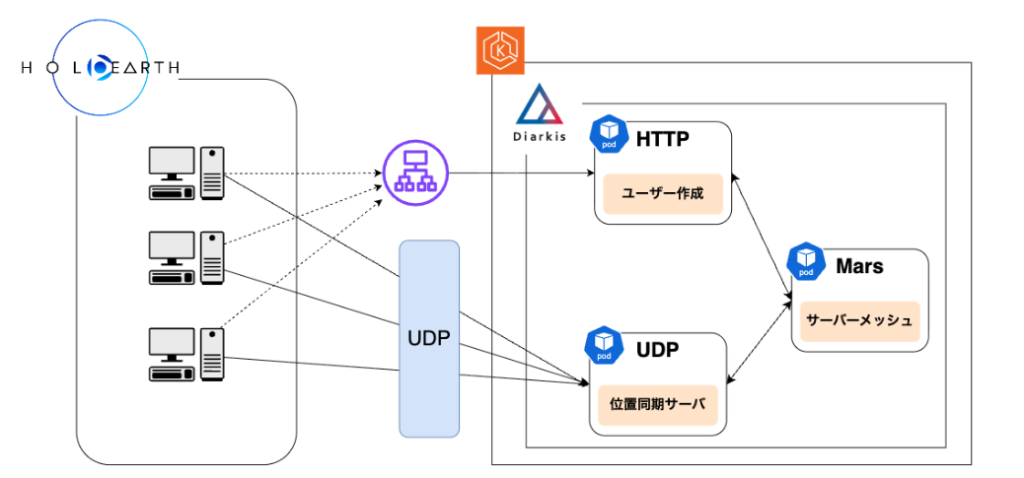
この位置同期システムを扱う上で必須となるEKSは、ほとんど塩漬け状態でした。そのため、まずは安定運用とコスト最適化を進めるため、EKSをSREチームで管理しました。Kubernetes運用におけるセルフサービス化を目指しました。
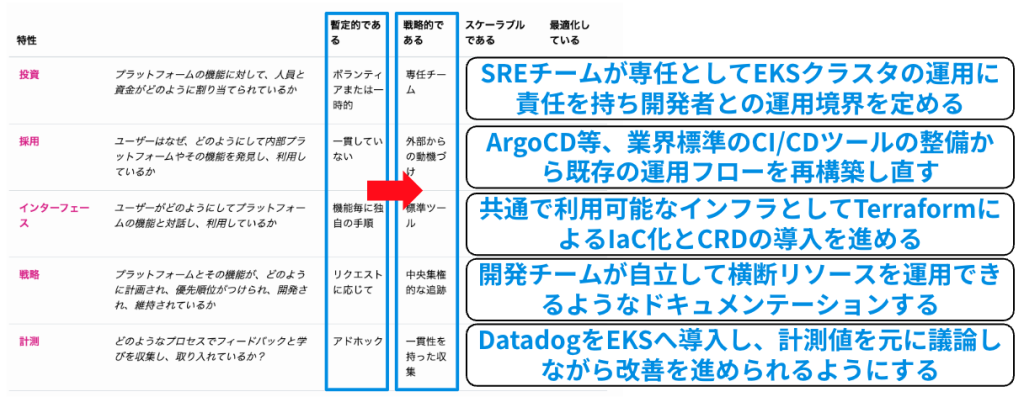
https://tag-app-delivery.cncf.io/whitepapers/platform-eng-maturity-model/#model-table
インフラのIaC化とGitOps導入
当時はeksctl create cluster後、ほぼ何もしていない状態のEKSが放置されており下記問題がありました。
・EKS関連リソースはIaC化されておらず全ての操作はeksctl(CFn)で手動管理
・EKS Addon/CRDは無し
・諸々のバージョンアップグレードに伴う検証フロー未整備
・GitOpsの未整備
そのため、まずはネットワークやEKSのリソースのIaC化を行いArgoCDによるGitOpsを行える状態へ整備を行いました。
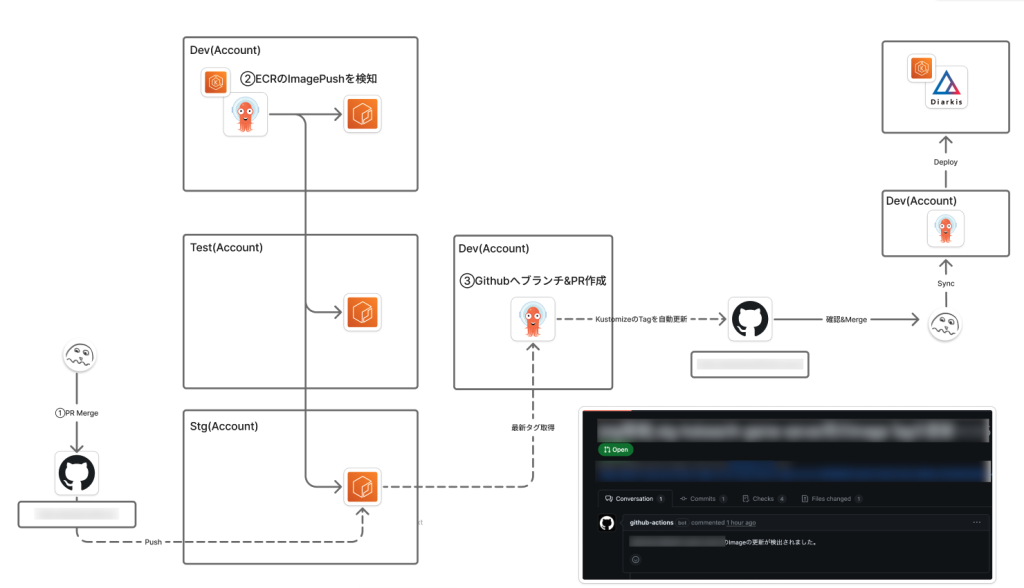

TerraformによるIaC化
Terraformはモノレポで管理し、下記を内包したTerraform実行フローをtfactionをベースで作成しています。
・エントリーポイントごとにjobの並列実行/lockfileの自動更新/trivy, tflintスキャンの実行
・Renovateによる各エントリーポイントごとのアップデートフローの整備(minReleaseAgeの指定/Group化によるPR数削減/ActionsのCommit hashの固定)
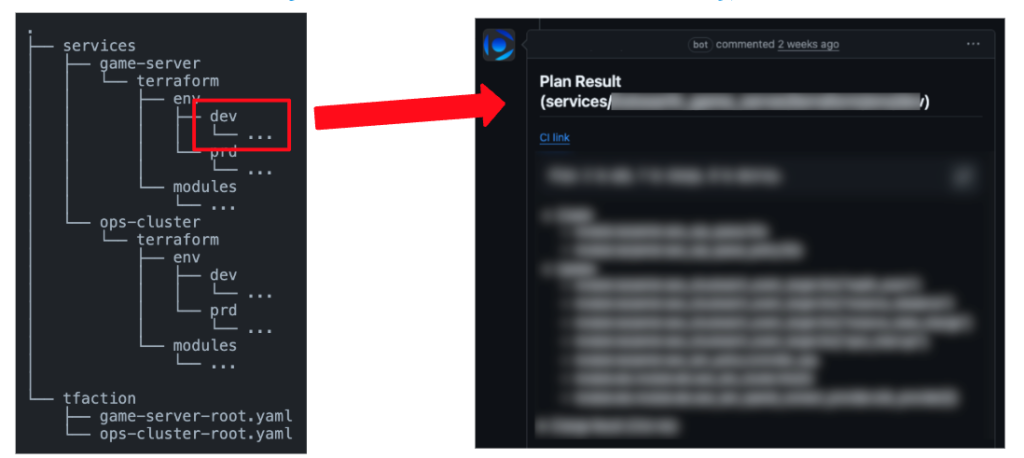
ArgoCD導入によるGitOps化
開発環境、本番環境それぞれにOpsClusterとしてArgoCD用のEKS(Auto Mode)を構築しGitOpsの基盤を構築しました。
・複数のAWSアカウントのワークロードクラスタを管理
・各環境のベースブランチに対してPRを作成するようにImage Updaterを構成
・GitHub Teamをベースとしてアクセス可能なApplicationをチームごとに制御
・Kustomize + Helmfileでリソースを管理
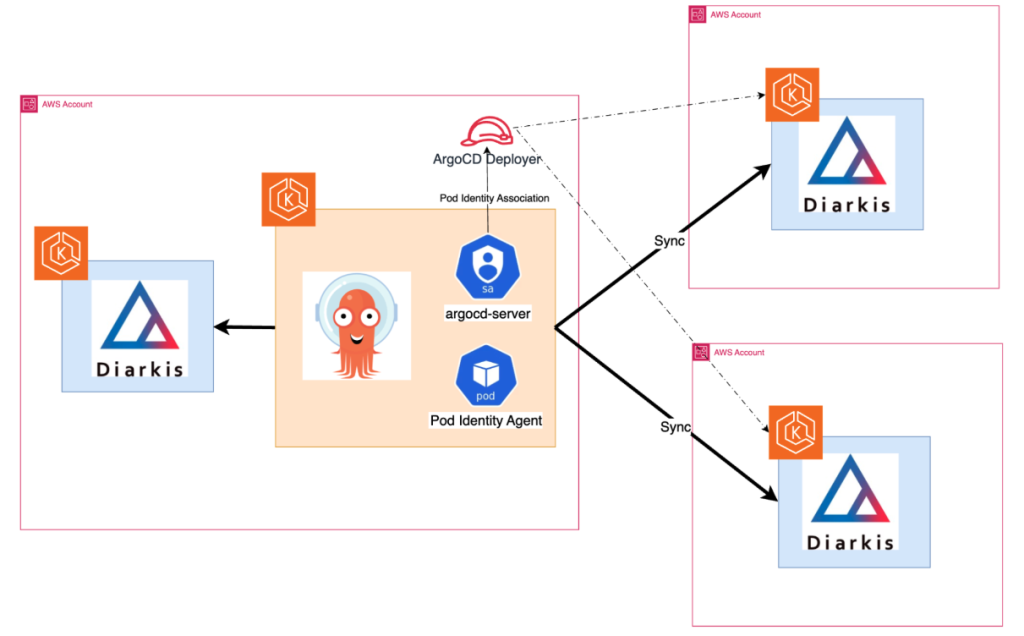
これらの対応によりワークロードクラスタに対して変更容易性を手に入れ、様々な改善策を施しやすくなりました。
サイジングとコスト適正化
ホロアースには様々なエリアがあり、そのほとんどのエリアで1 Roomが1 Node上の1 Podに対して割り当てられる仕組みになっています。
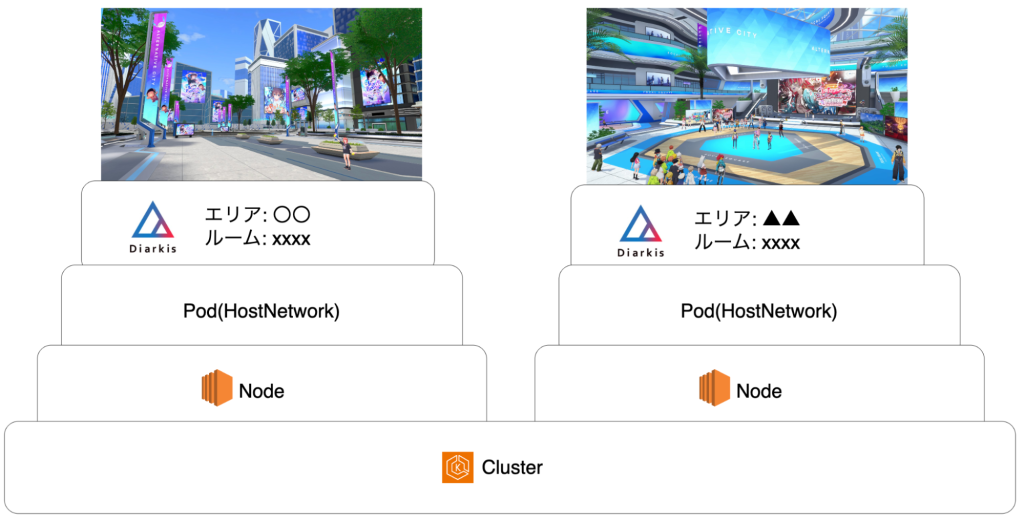
Diarkis Roomの制約により、位置同期は同じRoom(Hostnetworkが有効化されたPod)に対して行われます。そのため、1つのRoomに多数のユーザーが接続する場合、CPU負荷だけでなくネットワーク(PPS/帯域幅)がボトルネックになりがちです。
Botを用いて実際のユーザーが接続するのと同等の状況を作り、負荷試験を実施しました。これにより、1 Roomあたりの収容人数の適正化を行いました。
検証項目としては下記を定義しました。
・ENAドライバーにおける各種メトリクス(bw_in_allowance_exceeded / bw_out_allowance_exceeded / pps_allowance_exceeded)が観測されない
・CPU使用率に余裕がある(PodのCPU使用率がピーク時で20~30%)
・ベースラインの帯域幅を超えない
結果として、上記の条件を満たす1 Roomあたりの制限を100人と設定しました。これにより、利用インスタンスサイズをc5n.xlargeまで下げることで、コストを大幅に削減することができました。
オートスケールの刷新
ホロアースでは、ピークタイム以外で以下の2パターンのスケールが発生します。
・事前に予定されたイベント(タレントの降臨祭など)
・突発的なイベント(YouTubeでのタレントのホロアース配信など)
リアルタイムサーバー特有の「CPU使用率は低いが、Room人数は満員に近い」という状況に対応するため、カスタムメトリクスとKEDAを導入し、オートスケールを改善しました。
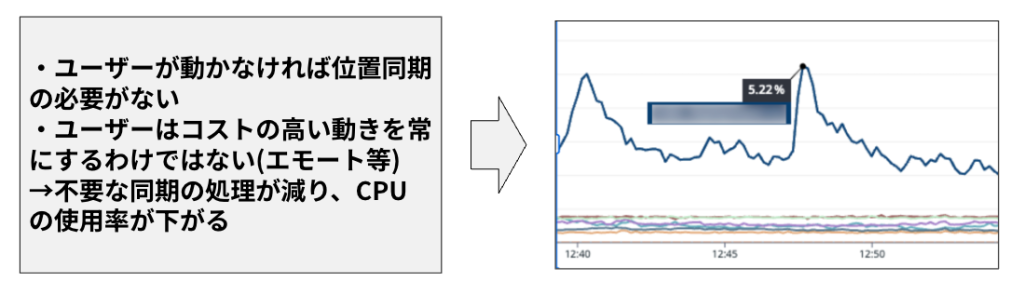
カスタムメトリクスの定義
Roomに対するカスタムメトリクスを、以下の通り新規に定義しました。
・Room占有率:1 Roomあたりの平均参加者数の割合
・アクティブRoom率:全 Roomのうち、参加者がいるRoom数の割合
これらのメトリクスを使用し、KEDAのDatadog Scalerを活用してオートスケールを行っています。
Datadog Scalerの活用
カスタムメトリクスをDatadogで計算し、それをトリガーにKEDAでPodをスケールさせる仕組みを構築しています。
・Cluster Agent Proxyを利用: Datadog APIのレート制限を考慮
・データの収集: Cluster Agent側の構成で4~5秒でカスタムメトリクスを収集
・Cluster Agent <-> KEDA間はBound Service Account Tokensを利用しTokenの管理を簡素化
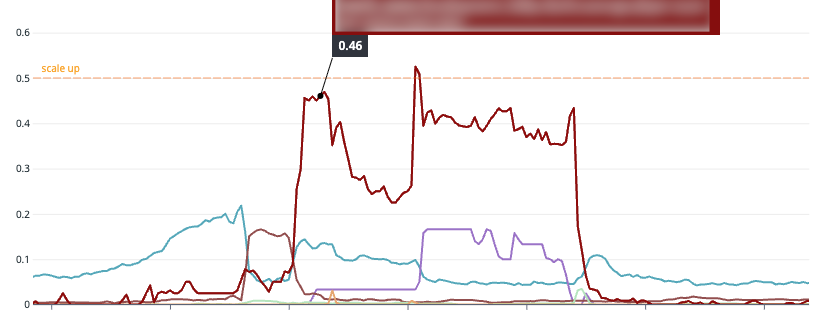
Metrics API Scalerの活用
タレント降臨イベントなどの計画された負荷に対しては、管理APIから必要数を指定して事前にスケールアウトできる仕組みも併用しました。
External metrics(MetricsType: Value)では、desiredReplicas = ceil(currentMetricValue / targetValue) の
計算式で評価されるため、targetValueを1に設定しておくことでAPIレスポンスの値がそのままDesiredReplica数となり、マニフェストを触らずにPodをスケールさせることができます。
Karpenterへの移行
ホロアースではNodeの管理コストを下げ、細かい中断制御を行うため、Cluster AutoScalerからKarpenterを全てのクラスタへ導入しました。
ホロアースで使用するEKSにおいて、NodeClassおよびNode Poolで考慮した点は以下の通りです。
[NodeClass]
・IMDSのホップカウント/AMIのバージョン固定
・VPC CNI のPrefix Delegationを有効化
[NodePool]
・Spot Instanceを優先的に使用
・expireAfter: Neverで運用、イベント時にNodeの入れ替えが起きないように調整
・DisruptionはDiarkisのWorkload Podが存在しない場合(consolidationPolicy: WhenEmpty) & ピーク時間以外のみ行う(budgets)
中断制御に関しては、特定時間内のみにスケールインできるようにKEDAのScaleDownPolicyをCronJobで調整しました。各種パラメータを調整することで、ユーザーのセッションを途切れさせずにスケールインを実現しています。

大規模利用に向けたパフォーマンス改善
ホロアースではイベント時にリアルタイムサーバーに対して数千人規模の同時接続が発生します。そのため、大量のNodeをプロビジョニングする必要があります。その際、パフォーマンス上の課題を解消する必要がありました。
メトリクス収集遅延
とあるイベント時にDiarkisのPrometheus Endpointに対してDatadogのCluster Agent経由でメトリクスを収集していた処理が遅延しました。
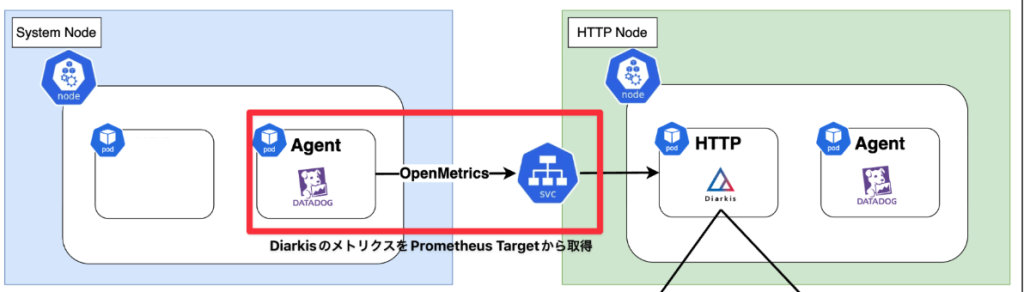
この影響でメトリクスの収集ができず、オートスケールやダッシュボードが停止しました。当時は暫定でタイムアウトを伸ばしましたが、1データポイントの取得に1分以上かかっており、実運用ができる状態ではありませんでした。
そこで、開発環境で複数のパターンで負荷実験を行い、原因を調査しました。
・Room数/Node (Pod) 数それぞれを増やすパターンで検証
・time curl -s http://<svc>/metrics/prometheus/v/3を実行し、平均を取得
結果として、Node数の増加がレイテンシ増加の主要因であることが判明しました。
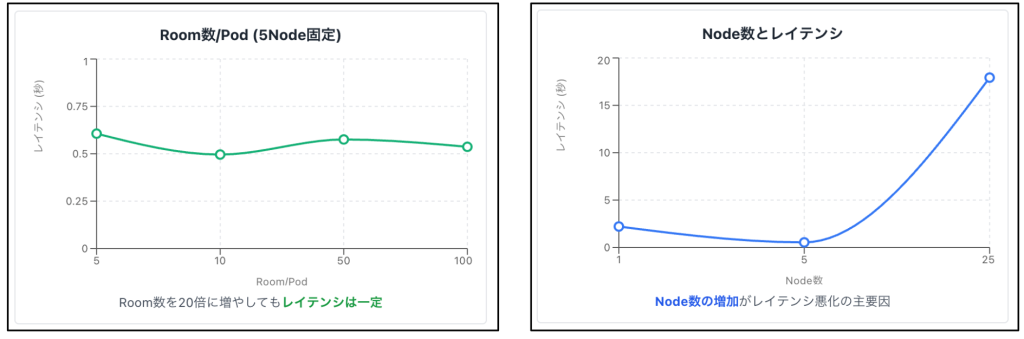
さらに、Node数が増えた際に何が起きているのかを確認するため、メトリクスを計算しているHTTP Serverに対してpprofを挿入し、確認を行いました。
詳細な結果は省略しますが、内部的に非効率な文字列の結合処理が大量に発生していたため、想定以上にCPUに負荷を与えている状況でした。最終的には、利用していたDiarkisにパッチを当てていただき、レイテンシを1秒未満に抑えることができ、問題を解消しました。
副次的な効果として、特定のHTTP Serverに対して計算処理でCPU負荷が偏っていた問題も解決しました。これにより、Node Poolの見直しを行い、HTTP Serverのコスト削減と可用性の向上にもつながりました。
CoreDNSの負荷対策
あるイベント時にCoreDNS全体への負荷が非常に高くなる現象が起きていました。
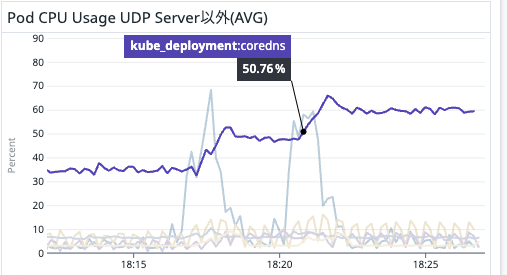
イベントに備えて事前スケールアウトを行う最中(2,000人規模〜)にCoreDNSのCPU使用率が100%付近に張り付きました。当時は直後にイベントを控えていたため、直接Replica数を増やして対応を行いました。
根本原因調査のため、開発環境でCoreDNSはデフォルトの2 ReplicaのままUDPサーバーの台数を増やし、CoreDNSのmetricsエンドポイントを確認しました。
結論として、存在しないドメインに対する名前解決が集中していたことによるCoreDNSの負荷増加が起きていました。
NOERROR: 517,036回
NXDOMAIN: 1,993,104回 ※該当するドメイン名が存在しない
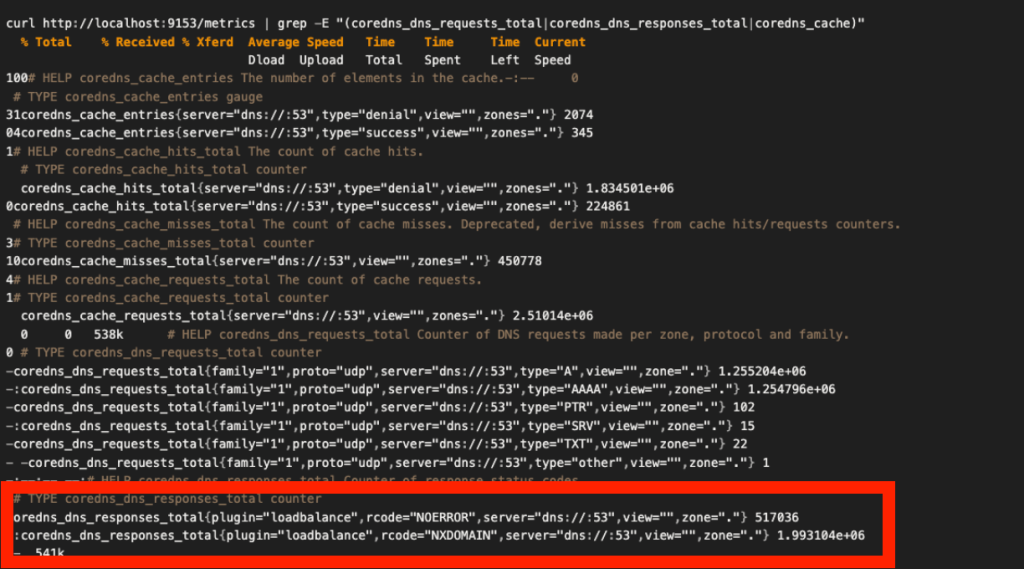
UDPサーバーを増やした時にこの状況が再現することはわかっていたため、各PodのDNS Configに問題があるのではないかとあたりをつけ、調査を進めました。
・/etc/resolv.confを確認したところ、search対象のドメインとndots:5が指定されています。(デフォルト値)

この設定により、ドットの数が5未満の場合、サーチリストに指定されているドメインが末尾に追加されて名前解決が行われます。結果として、存在しないドメイン名へのアクセスが大量発生していたことが分かりました。
実際にCoreDNSのログを見ると、存在しない内部サービスに向けてのクエリが大量に試行されていました。
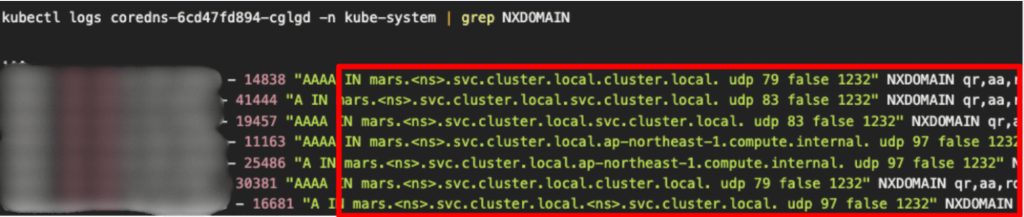
そこで、DeploymentのdnsConfigをndots: 1として設定し、常にFQDNとして解決されるように修正しました。
https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#pod-dns-config
同等の対応をDatadogのNodeAgentなどにも行うことで、NXDOMAINの数はほぼ0になりました。その結果、Replica数2の状態でCoreDNSのCPU使用率はピーク時の4分の1程度に減らすことができました。
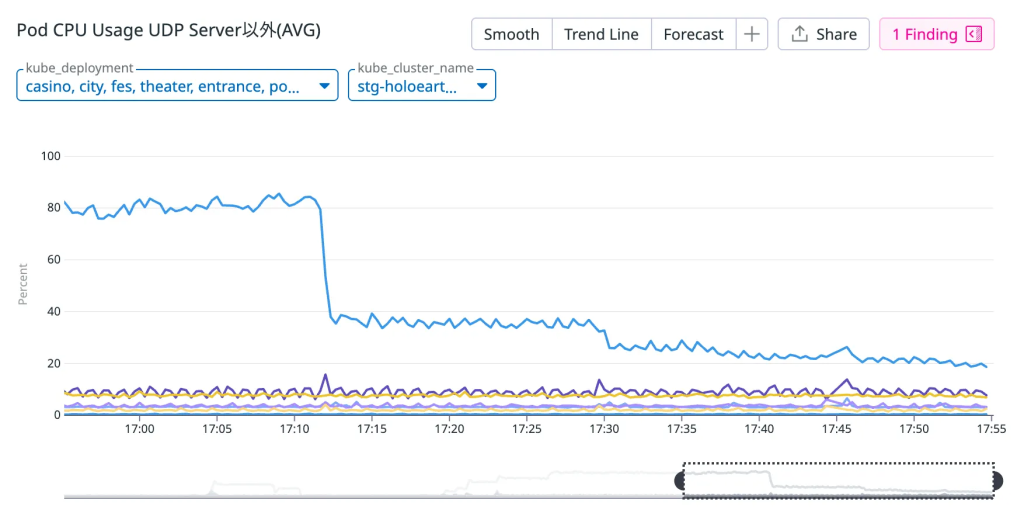
また、EKS アドオン側でオートスケールの設定を行うことで、さらにPod数が増えた場合でも対応できるように構成の変更を行いました。
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/coredns-autoscaling.html
その他改善
メール配信
2025年にリリースされたUGC機能において、ユーザーが作成したオリジナルアイテムの販売が可能になりました。 これに伴い、「アイテム購入通知」や「在庫切れ通知」といった即時性が求められる通知を行うメール基盤が必要となりました。
スパイクアクセスと到達率の維持
ホロアースの特性上、人気クリエイターが新作アイテムを販売開始した瞬間にそのフォロワーに対して一斉に通知を行うようなトラフィックが発生する可能性があります。 既存のAWS環境との親和性から開発当時はAWS SESを使った構成が取られていました。
しかし、本運用が近づいたタイミングで改めてメール配信の性能要件を整理したところ、複雑な構成や管理が必要になる懸念が出てきました。
スロットリングとアーキテクチャの複雑化
・数千〜数万件規模の即時配信を行う場合、SESの送信レート制限に抵触するリスクがある
・スループットを確保するには、複数リージョンにまたがってリクエストを分散させるような複雑なキューイング構成が必要となる
レピュテーション管理
・今後ユーザー数が増加していく中で、IPレピュテーションを維持し、メールの到達率を担保し続ける運用コストが懸念される
・バウンスや苦情発生時、サプレッションリストに登録されてからのハンドリングや、送信リストのクレンジングが行えていない場合のAWSアカウント停止リスクなどに懸念がある
参考にさせていただいた運用事例
運用事例やチームが達成したい配信性能を比較しながら検討した結果、ホロアースではSESではなくSendGridを採用しました。メール配信自体をマネージドサービスに寄せるようにしています。幸いなことにSendGridのGo SDKも充実しており、移行の手間はほとんどかかりませんでした。
結果として、当初かかる想定だった開発工数もかからず、サービスの成長に合わせてプランを変更していくことで、メール配信の対応ができるようになりました。
API Server(Fargate)のArm移行
API Server群はECS Fargateで運用されており、ほぼ全てがx86ベースのプロセッサ上で稼働していました。これ自体に問題はありませんでしたが、AWSが推奨するGraviton プロセッサが存在します。コスト削減のため、利用を検討することにしました。
移行時の懸念点は以下の3つでした。
・Armベースとなるので当時のビルド環境(GitHub Actions上のlinux/amd64 Runner)だとビルドが極端に遅くなる(QEMUを利用するため)
・各種メインコンテナのランタイム/サイドカーのImageがArm対応可能か(Datadog/Fluent Bit)
・パフォーマンス上の懸念はないか
基本的に利用していたアプリケーションのイメージはArmに対応していたため、ビルド環境およびパフォーマンスに関して調査を行いました。

[コスト]
1. Fargate TaskをArmで置き換えた場合の月の削減額を割り出しました。
・当時の計算式: Task数× {vCPU×(0.05056-0.04045) + Mem(GB)×(0.00553-0.00442)} × 稼働時間 × 日数
2.ECRへのPush用のワークフローの月あたり合計実行回数および1回あたりの平均実行時間から、各ビルドパイプラインを構成した場合のコストを割り出しました。
1と2の結果から、どのパターンでもArmへの置き換えによるコスト削減額が支配的でした。そのため、コスト面では移行は問題ないと判断しました。
[パフォーマンス]
パフォーマンスに関しては、CPUのベンチマークを行っている記事を参考にしつつ、開発チームで行っている負荷試験で今まで通りの期待RPSを捌けることを確認しました。
結果として、Arm移行に伴うコスト削減効果があり、性能劣化はないと判断しました。運用のシンプルさと効果を重視し、GitHub ActionsをArm Runnerへ切り替え、FargateをGraviton対応のタスクに入れ替えました。
まとめ
ホロアースのSREとして取り組んできた事例を紹介しました。これらの取り組みによりコスト削減やイベントを安定して開催できる基盤を整えることができました。まだ改善途中ではありますが、一人でも多くのユーザーにホロアースを遊んでもらえるように尽力していく所存です。
最後までご覧いただきありがとうございます。カバー株式会社ではエンジニアを積極的に採用しております。この記事を読んでご興味をお持ちいただけましたら、以下のリンクよりご応募をお願いいたします。
https://hrmos.co/pages/cover-corp/jobs?category=1632692806534664193



